Our Blog
How WordPress 5.3 Is Changing The Way You Block Google Indexing

It is a well-known fact that WordPress is the most popular web development platform in the world. Ask anyone about the reasons for its immense following and people will start listing convenience and ease of use as reasons. However, there is one major reason that most people fail to notice. The team running the open-source CMS resolves all kinds of issues, no matter how minor, that emerge in different aspects of the platform. One such problem that was addressed recently is the way to block Google indexing. WordPress is an SEO-friendly platform with numerous beneficial features. However, there are situations when people do not want the world’s largest search engine to register the presence of their pages. The CMS had a facility for such users but it did not truly stop Google from indexing a page. Let’s dive into the topic to know more about it.
What Is Indexing?
A search engine’s index is its database where it keeps all the information related to the websites it was able to discover. Indexing happens when a search engine finds a page and adds it to the database. When search engines like Google find a URL, they look at all elements on it including content. Their algorithms analyze the text, media like photos and videos and almost everything that is included in the HTML code of the page. This extensive analysis is called crawling that forms the basis of how search engines finalize their results rankings. As we mentioned earlier, SEO-friendliness is an in-built feature of WordPress website development. All posts and pages generated in the CMS are indexed by default. This is because the default setting permits search engines to take a look at the pages.
Many people think that indexing and crawling are one and the same. However, this is not the case as a page cannot be crawled but it can still be indexed. Consider this example to understand the difference. Let’s say you are reading a book and you see the table of contents right at the beginning. Now when you flip the pages, you find some of them are missing. Now you know the names of the chapters that are missing but you are unaware of their exact content. Knowing the names of the chapters is similar to indexing while not able to read them is like a search engine being unable to crawl.
Why Do You Need To Block Indexing?
Beginners must be wondering why do you need to block Google indexing. After all, everyone wants their websites to be on top of the relevant search results and blocking will be detrimental to that objective. Let’s say you are making some modifications to your interface in a staging environment and it accidentally gets indexed. Now if people are directed to it through a search result and find that the content is absent or incomplete, then they will leave it dissatisfied. Some users may report the link to the search engine. The bounce rate of the interface will also be high and when Google notices this, it can downgrade your website. In such scenarios, it becomes necessary to stop the search engine from registering your website’s presence for some time.
How Was Indexing Blocked Until Now?
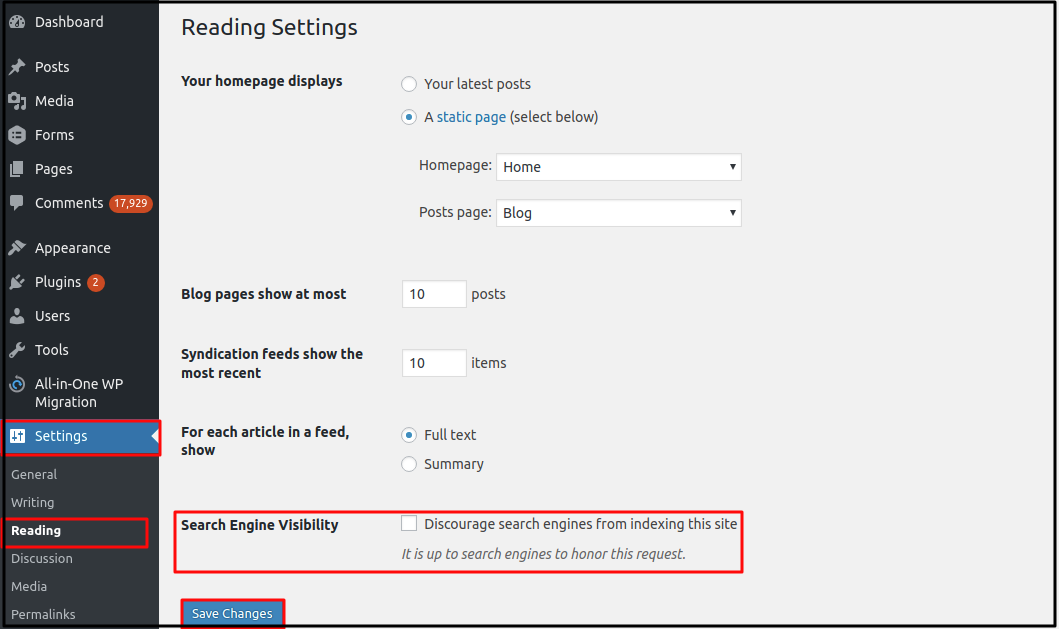
People who did not want Google to index their pages until now used a convenient WordPress feature. They accessed the Reading settings of their installation by visiting Settings > Reading in their dashboard. There they simply checked the box against the “Discourage search engines from indexing this site” in the Search Engine Visibility section. Then they pressed the Save Changes tab to confirm their action.
This method used the Robots.txt file to stop search engines from indexing the website. This is the basic format of the file.
User-agent: *
Disallow: /
The asterisk in the first line indicates that the directive will apply to all search engine bots. The “/” in the second line indicates that none of the pages must be visited. Users can include URL strings between two slashes to exclude only specific pages to be blocked. Similarly, they can include the name of a particular user agent to stop it from indexing.
What Was The Problem In The Current Blocking Method?
The existing method did not completely stop the world’s number 1 search engine from indexing a page. It only barred it from crawling the property. In case, Google was able to find the URL, it added the link to its index. This means that using the Robots.txt directive was not an effective method to stop the indexing of a page.
How WordPress 5.3 Is Changing The Manner Of Blocking Indexing?
WordPress 5.3 has junked the Robots.txt method in favor of the Robots Meta Tag way. This is a much more dependable method to truly achieve the objective of blocking. There are four main parameters in Robots Meta Tag namely, Follow, Index, Nofollow, and Noindex. As its name suggests, follow commands a crawler to follow the links on a page while nofollow tells them not to follow the links. Similarly, index tells the bot to index a page while noindex prohibits it from indexing. This approach eliminates confusion and clearly prevents search engine bots from indexing specific pages.
Conclusion
This new method to block Google indexing will help webmasters in efficiently optimizing their properties from search engines. However, new users who are finding it difficult to adopt the new approach can hire a WordPress developer from HireWPGeeks by calling, emailing, or filling the form at the website.